|
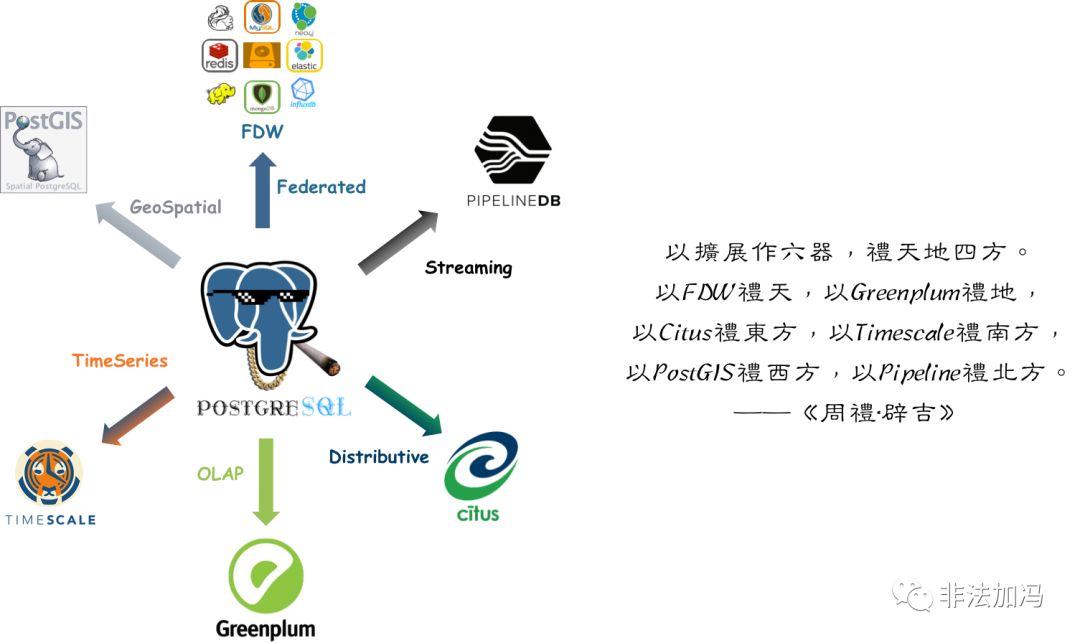
全栈数据库 成熟的应用可能会用到许许多多的数据组件(功能):缓存,OLTP,OLAP/批处理/数据仓库,流处理/消息队列,搜索索引,NoSQL/文档数据库,地理数据库,空间数据库,时序数据库,图数据库。传统的架构选型呢,可能会组合使用多种组件,典型的如:Redis + MySQL + Greenplum/Hadoop + Kafuka/Flink + ElasticSearch,一套组合拳基本能应付大多数需求了。不过比较令人头大的就是异构系统集成了:大量的代码都是重复繁琐的搬砖代码,干着把数据从A组件搬运到B组件的事情。 在这里,MySQL就只能扮演OLTP关系型数据库的角色,但如果是PostgreSQL,就可以身兼多职,One handle them all,比如: - OLTP:事务处理是PostgreSQL的本行
- OLAP:citus分布式插件,ANSI SQL兼容,窗口函数,CTE,CUBE等高级分析功能,任意语言写UDF
- 流处理:PipelineDB扩展,Notify-Listen,物化视图,规则系统,灵活的存储过程与函数编写
- 时序数据:timescaledb时序数据库插件,分区表,BRIN索引
- 空间数据:PostGIS扩展(杀手锏),内建的几何类型支持,GiST索引。
- 搜索索引:全文搜索索引足以应对简单场景;丰富的索引类型,支持函数索引,条件索引
- NoSQL:JSON,JSONB,XML,HStore原生支持,至NoSQL数据库的外部数据包装器
- 数据仓库:能平滑迁移至同属Pg生态的GreenPlum,DeepGreen,HAWK等,使用FDW进行ETL
- 图数据:递归查询
- 缓存:物化视图
以擴展作六器,禮天地四方。 以FDW禮天,以Greenplum禮地, 以Citus禮東方,以Timescale禮南方, 以PostGIS禮西方,以Pipeline禮北方。 ——《周禮·辟吉》
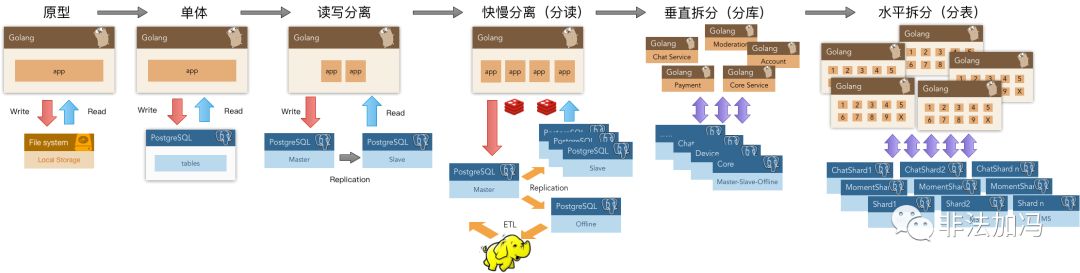
在探探的旧版架构中,整个系统就是围绕PostgreSQL设计的。几百万日活,几百万全局DB-TPS,几百TB数据的规模下,数据组件只用了PostgrSQL。独立的数仓,消息队列和缓存都是后来才引入的。而且这只是验证过的规模量级,进一步压榨PG是完全可行的。 因此,在一个很可观的规模内,PostgreSQL都可以扮演多面手的角色,一个组件当多种组件使。虽然在某些领域它可能比不上专用组件,至少都做的都还不赖。而单一数据组件选型可以极大地削减项目额外复杂度,这意味着能节省很多成本。它让十个人才能搞定的事,变成一个人就能搞定的事。 对绝大多数应用而言,终其生命周期都不会有超出Pg能力范围之外的数据量级。为了不需要的规模而设计是白费功夫,实际上这属于过早优化的一种形式。 此外,只有当没有单个软件能满足你的所有需求时,才会存在分拆与集成的利弊权衡。集成多种异构技术是相当棘手的工作,如果真有那么一样技术可以满足你所有的需求,那么使用该技术就是最佳选择,而不是试图用多个组件来重新实现它。 当业务规模增长到一定量级时,可能不得不使用基于微服务/总线的架构,将数据库的功能分拆为多个组件。但PostgreSQL的存在极大地推后了这个权衡到来的阈值,而且分拆之后依然能继续发挥重要作用。 运维友好 当然除了功能强大之外,Pg的另外一个重要的优势就是运维友好。有很多非常实用的特性: - DDL能放入事务中,删表,TRUNCATE,创建函数,索引,都可以放在事务里原子生效,或者回滚。
- 这就能进行很多骚操作,比如在一个事务里通过RENAME,完成两张表的王車易位。
- 能够并发地创建、删除索引,添加非空字段,重整索引与表(不锁表)。
- 这意味着可以随时在线上不停机进行重大的模式变更,按需对索引进行优化。
- 复制方式多样:段复制,流复制,触发器复制,逻辑复制,插件复制等等。
- 这使得不停服务迁移数据变得相当容易:复制,改读,改写三步走,线上迁移稳如狗。
- 提交方式多样:异步提交,同步提交,法定人数同步提交。
- 这意味着Pg允许在C和A之间做出权衡与选择,例如交易库使用同步提交,普通库使用异步提交。
- 系统视图非常完备,做监控系统相当简单。
- FDW的存在让ETL变得无比简单,一行SQL就能解决。
- FDW可以方便地让一个实例访问其他实例的数据或元数据。在跨分区操作,数据库监控指标收集,数据迁移等场景中妙用无穷。同时还可以对接很多异构数据系统。
还有很多功能,就不一一列举了。 生态健康 PostgreSQL的生态也很健康,社区相当活跃。 相比MySQL,PostgreSQL的一个巨大的优势就是协议友好。PG采用类似BSD/MIT的PostgreSQL协议,差不多理解为只要别打着Pg的旗号出去招摇撞骗,随便你怎么搞,换皮出去卖都行。君不见多少国产数据库,或者不少“自研数据库”实际都是Pg的换皮或二次开发产品。 当然,也有很多衍生产品会回馈主干,比如timescaledb,pipelinedb, citus这些基于PG的“数据库”,最后都变成了原生PG的插件。很多时候你想实现个什么功能,一搜就能找到对应的插件或实现。开源嘛,还是要讲一些情怀的。 Pg的代码质量相当之高,注释写的非常清晰。C的代码读起来有种Go的感觉,代码都可以当文档看了。能从中学到很多东西。相比之下,其他数据库,比如MongoDB,看一眼我就放弃了读下去的兴趣。 而MySQL呢,社区版采用的是GPL协议,这其实挺蛋疼的。要不是GPL传染,怎么会有这么多基于MySQL改的数据库开源出来呢?而且MySQL还在乌龟壳的手里,让自己的蛋蛋攥在别人手中可不是什么明智的选择,更何况是业界毒瘤呢?Facebook修改React协议的风波就算是一个前车之鉴了。 问题 当然,要说有什么缺点或者遗憾,那还是有几个的: - 因为使用了MVCC,数据库需要定期VACUUM,需要定期维护表和索引避免膨胀导致性能下降。
- 没有很好的开源集群监控方案(或者太丑!),需要自己做。
- 慢查询日志和普通日志是混在一起的,需要自己解析处理。
- 官方Pg没有很好用的列存储,对数据分析而言算一个小遗憾。
当然都是些无关痛痒的小毛小病,不过真正的问题可能和技术无关…… 说到底,MySQL确实是最流行的开源关系型数据库,没办法,写Java的,写PHP的,很多人最开始用的都是MySQL…,所以Pg招人相对困难是一个事实,很多时候只能自己培养。不过看DB Engines上的流行度趋势,未来还是很光明的。
| 



 转播
转播 分享
分享 淘帖
淘帖